
稀疏表达是近年来SP, ML, PR, CV领域中的一大热点,文章可谓是普天盖地,令人目不暇给。老板某门课程的课程需要大纲,我顺道给扩展了下,就有了这个上中下三篇介绍性质的东西。遗憾的是,我在绝大多数情况下实在不算是一个勤快的人,这玩意可能充满bug,更新也可能断断续续,尽请诸位看官见谅了。顺道一提,ICCV09有一个相关的。
据传博文里公式数量和其人气是成反比例关系的,一个公式可以驱散50%的读者,我写完这个(上)之后点了点公式数量,觉得大约是要无人问津了。所以,在介绍稀疏表达之前,让我们先来展示下其在computer vision中的应用,吸引下眼球。
首先是图像恢复(以前有人贴过Obama还记得不),由左侧图像恢复出右侧结果
然后是类似的图像inpainting
然后是图像去模糊,左上为输入模糊图像,右下为输出清晰图像及估计的相机运动(其实是PSF),中间均为迭代过程:
再然后是物体检测(自行车),左侧输入图像,中间为位置概率图,右侧为检测结果
当然我个人还推荐Yi Ma的,这个在对抗噪声的效果上很棒,比如下图中左侧的那张噪声图像(你能辨认是哪位不?这方法可以!)
且说sparse representation这个概念,早在96-97年的时候就火了一把。最著名的大约要数Nature上的某篇文章,将稀疏性加入least square的regularization,然后得到了具有方向特性图像块(basis)。这样就很好的解释了初级视皮层(V1)的工作机理,即对于线段的方向选择特性。几乎同一时期,著名的LASSO算法也被发表在 J. Royal. Statist. Soc B。Lasso比较好的解决了least square (l2 norm) error + l1 norm regularization的问题。然而,这个时候绝大多数人没有意识到(或者没法解决)这l1 norm和稀疏性之间的联系。其实早在这之前,Osher等人提出的Total Variation (TV)已经包含了l1 norm的概念了,只不过TV原本是连续域上的积分形式。(啥?你不知道Osher…想想Level Set吧)
在进入现代的压缩感知、稀疏表示这一课题前,让我们来首先回顾下这一系列问题的核心,即线性方程组
 ,通常而言是满秩的。向量
,通常而言是满秩的。向量 。现在已知
。现在已知 ,求解
,求解 。学过线性代数的同学可能都会说:这个不难啊,因为
。学过线性代数的同学可能都会说:这个不难啊,因为 , 故而这个方程组是欠定的,所以有无穷多组解啊,咱还可以算算基础解系啥的…
, 故而这个方程组是欠定的,所以有无穷多组解啊,咱还可以算算基础解系啥的… 但是如果我们希望其解尽可能的稀疏:比如 (即中非零元个数)尽可能的小。那么问题就会变得比较微妙了,下图给出了问题的形象示意。
(即中非零元个数)尽可能的小。那么问题就会变得比较微妙了,下图给出了问题的形象示意。
 ,如何选择最少个数的基向量,重构给定向量
,如何选择最少个数的基向量,重构给定向量 ,其严格定义可以写成
,其严格定义可以写成
时光之轮播快到2003~2004年,Donoho & Elad做了一个很漂亮的证明,如果矩阵 满足某种条件,具体而言:
满足某种条件,具体而言:
 那么上文提及的0范数优化问题具有唯一的解。这里的
那么上文提及的0范数优化问题具有唯一的解。这里的 是个比较诡异(请允许我使用这词)的定义:最小的线性相关的列向量集所含的向量个数(吐槽:明白了么,我做TA的时候就被这个问题问倒了)。本来想在这个概念上唠叨两句,后来发现了Elad的一个,清晰明了。
是个比较诡异(请允许我使用这词)的定义:最小的线性相关的列向量集所含的向量个数(吐槽:明白了么,我做TA的时候就被这个问题问倒了)。本来想在这个概念上唠叨两句,后来发现了Elad的一个,清晰明了。 即便是唯一性得到了证明,求解这个问题仍然是NP难的。科研的车轮滚滚向前,转眼到了2006年,传奇性的华裔数学家Terrence Tao登场了,Tao和Donoho的弟子Candes合作证明了在RIP条件下,0范数优化问题与以下1范数优化问题具有相同的解:
 其中RIP条件,即存在满足某种条件的(与N相关)常数:
其中RIP条件,即存在满足某种条件的(与N相关)常数:
 RIP条件是对于矩阵列向量正交性的一种衡量(此处咱就不细说了)。其实早在1993年Mallat就提出过Mutual Coherence对于正交性进行度量,并提出了下文还要提及的matching pursuit方法。
RIP条件是对于矩阵列向量正交性的一种衡量(此处咱就不细说了)。其实早在1993年Mallat就提出过Mutual Coherence对于正交性进行度量,并提出了下文还要提及的matching pursuit方法。 实际上以上的1范数优化问题是一个凸优化,故而必然有唯一解,至此sparse representation的大坑初步成型。总结一下:
1. 如果矩阵满足 ,则0范数优化问题有唯一解。 2. 进一步如果矩阵满足RIP条件,则0范数优化问题和1范数优化问题的解一致。 3. 1范数优化问题是凸优化,故其唯一解即为0范数优化问题的唯一解。
,则0范数优化问题有唯一解。 2. 进一步如果矩阵满足RIP条件,则0范数优化问题和1范数优化问题的解一致。 3. 1范数优化问题是凸优化,故其唯一解即为0范数优化问题的唯一解。 进一步可以考虑含噪声情况,即
 可以得到相似的结果,有兴趣的同学可以查阅相关文献。理论坑只有大牛能挖,但一般人也能挖挖这个优化算法啊,于是SP、ML、CV邻域里都有做这个优化算法的,这个出招可就真是五花八门了。据我所知,大致可以分为三大流派: 1. 直接优化 一般的方法是greedy algorithm,代表有Matching Pursuit, Orthogonal Matching Pursuit 2. 优化
可以得到相似的结果,有兴趣的同学可以查阅相关文献。理论坑只有大牛能挖,但一般人也能挖挖这个优化算法啊,于是SP、ML、CV邻域里都有做这个优化算法的,这个出招可就真是五花八门了。据我所知,大致可以分为三大流派: 1. 直接优化 一般的方法是greedy algorithm,代表有Matching Pursuit, Orthogonal Matching Pursuit 2. 优化 还记得上面提到的LASSO么,这就是它的模型。 3. 如果已知拉格朗日乘子,优化无约束凸优化问题
还记得上面提到的LASSO么,这就是它的模型。 3. 如果已知拉格朗日乘子,优化无约束凸优化问题 解这个的方法现在基本上soft thresholding的方法一统天下,常见的有coordinate descent, Bregman Iteration (又是Osher)等 4. 如果未知拉格朗日乘子,优化
解这个的方法现在基本上soft thresholding的方法一统天下,常见的有coordinate descent, Bregman Iteration (又是Osher)等 4. 如果未知拉格朗日乘子,优化 这类方法又叫Homotopy,可以认为是3的扩展。核心出发点是objective function是
这类方法又叫Homotopy,可以认为是3的扩展。核心出发点是objective function是 的分段线性函数。
的分段线性函数。 除此之外,还有利用p范数逐次逼近0范数的方法等等,此处不再赘述。顺道说一句,稀疏表示在不同的领域连名称都不同,搞信号的管这个叫basis pursuit,搞统计的叫l1 regularization….然后,让我们把话题拉回到Nature的那篇文章:如果我们不知道矩阵,只知道一堆向量 。我们应当如何构造,使得在这一字典(矩阵)下的表示最稀疏?类比以上过程,这个问题被称为Dictionary Learning,可以写成以下优化问题:
。我们应当如何构造,使得在这一字典(矩阵)下的表示最稀疏?类比以上过程,这个问题被称为Dictionary Learning,可以写成以下优化问题:
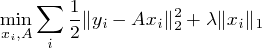
这个东西可就相对麻烦了,最关键的是这个优化不是凸的(优化变量相乘)。所以一般的想法是block descent:首先固定 ,优化
,优化 (相当于多个独立的1范数优化问题);其次将计算出的固定,优化,这就是一个(可能带约束)的least square问题。如此反复,直到算法收敛到某个(局部)极小值。实际上解这个问题的方法目前有三种:efficient sparse coding algorithm NIPS 06; K-SVD tsp 06; Online dictionary learning for sparse coding, ICML 09 & JMLR 10。前两种都是batch的方法,后一种是online的,据个人测试最后一种的方法比前两者要快很多很多….下面这个是我利用ICML09的方法从1200张彩色图像中训练出一组过完备基,具有比较好的方向特性。
(相当于多个独立的1范数优化问题);其次将计算出的固定,优化,这就是一个(可能带约束)的least square问题。如此反复,直到算法收敛到某个(局部)极小值。实际上解这个问题的方法目前有三种:efficient sparse coding algorithm NIPS 06; K-SVD tsp 06; Online dictionary learning for sparse coding, ICML 09 & JMLR 10。前两种都是batch的方法,后一种是online的,据个人测试最后一种的方法比前两者要快很多很多….下面这个是我利用ICML09的方法从1200张彩色图像中训练出一组过完备基,具有比较好的方向特性。
最后,还记得本文开头的那些demo么?INRIA做了一个sparse representation的matlab工具包,虽然不开源,但其效率(大部分时候)是现有公开工具包之冠(底层用了intel的MKL),利用这个工具包,几行简单的matlab代码就可以几乎实现以上提及的所有demo了….大家有兴趣的话,欢迎尝试^_^
下期预告:借着collaborative filter的东风,Candes在08年又挖出了matrix completion的新坑。于是,当向量的1范数推广到矩阵的迹范数(trace norm)之后…..